今天要來下載 Taiwan LLaMa 模型啦,在 Ferris 的介紹下 Taiwan LLaMa 跟 Iron LLaMa 也聯手了!
昨夜烤肉時,想著來下載一下模型吧,打開 下載的頁面 一看,啪,那麼多,到底要下載哪個才對?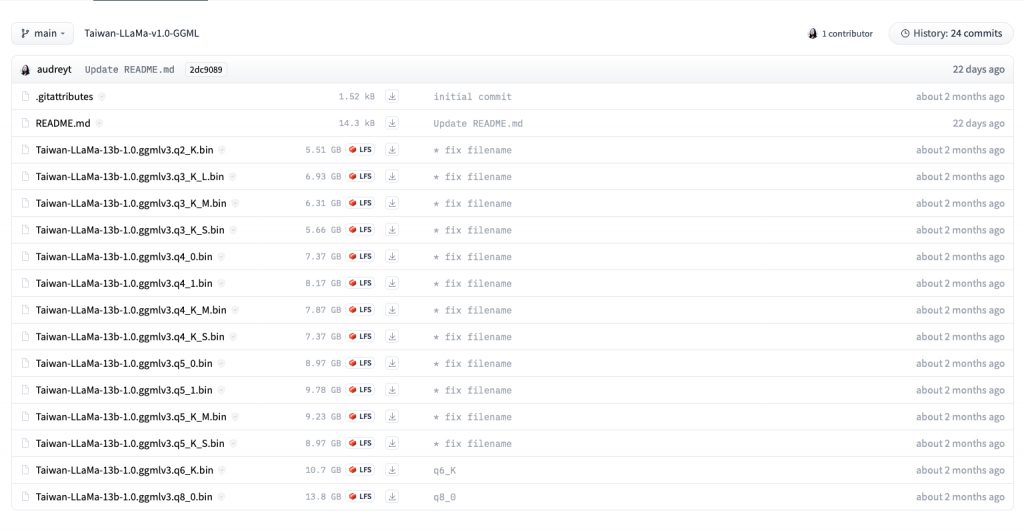
好像就這麼懂了馬邦德的感覺:
所以今天中秋後緊急加烤,不是!緊急加開,GGML 模型版本那麼多,怎麼選擇適合自己的檔案?
由於大型語言模型(LLMs)的尺寸通常都很巨大,因此模型量化已成為一種重要的技術。
透過減少其權重的精度,我們可以在保留大部分模型性能的情況下,節省記憶體並加快推論的速度。
而近年得力於 8-bit 與 4-bit 量化的發展,人人都有機會在自己的電腦上讓 LLMs 跑起來:
加上 LLaMa 模型的發表以及可大幅減少微調所需參數的技術 (例如 LoRA),使得本機端 LLM 的生態系統日益茁壯,如今已可與 OpenAI 的 GPT-3.5 或 GPT-4 同台較量。
如果在 Hugging Face🤗 逛一圈,會發現許多模型名稱後面接著 GPTQ、AWQ、GGML 等後綴,這些指的都是量化的方法,又被稱為窮鬼救星!
在 [Day 10] - 鋼鐵草泥馬 🦙 LLM chatbot 🤖|專案簡介 的時候我們稍微提到了 GGML,而我們今天再來近一步剖析它。
GGML 是由 llama.cpp 的作者 Georgi Gerganov 所建立的 C 語言機器學習函式庫,而 GG 就來自於作者的名字縮寫,真的是差一點就變成 JoJoML 了
GGML 不僅提供了張量等機器學習的基本元素,還提供了一個獨特的二進制格式,用以發佈 LLM。
它被設計為與 llama.cpp 共同使用,如此一來便能提供高效率的 LLM 推論,我們可以把 GGML 的模型載到 CPU 上進行推論 (現在也有 GPU 支援了)。
由於 Rustformers 的基礎為 llama.cpp,所以它所支援的模型自然是 GGML 格式。
GGML 最近被更新的 GGUF 取代了。這種新格式被設計成可擴展的,以便新功能不會破壞現有模型的相容性。它還把包括特殊 token、RoPE 縮放參數等 metadata 集中在一個檔案中。總的來說,它解決了一些歷史性的痛點,並應該是具有前景的,Rustformers 也有對其進行支援的計畫,請參考 Support GGUF #365。
回到前面打開的 下載頁面,數一數可以發現有 14 個檔案使用了 LFS,而這正對應到了 14 種不同的量化方式。
它們有一套命名邏輯,q 後面的數字代表的是用了幾個 bit 來儲存權重,也就是所謂的精度,而下底線 _ 後面的則對應到不同的變體。
詳細說明可以參考 TheBloke/Llama-2–13B-chat-GGML:
首先我們可以看到裡面提到了新的 k-quant methods,簡單翻譯如下:
裡面提到的 type-0 與 type-1,是指現有的 GGML 量化類型:
延伸閱讀:Quantization 的那些事
知道新的 k-quant 方法是什麼意思之後,我們就可以開始說明 14 個變體分別代表什麼了:
2-Bit Quantization
attention.vw、feed_forward.w2 與後面提到的各種張量都是指 Transformer 的架構。
3-Bit Quantization
4-Bit Quantization
5-Bit Quantization
6-Bit Quantization
8-Bit Quantization
從上面的說明來看,我想最推薦的應該是 Q5_K_M,因為它最能保留大部分的模型性能。
而如果想要多省一些記憶體則可以改用 Q4_K_M。
總的來說,K_M 版本在表現上應該會優於 K_S 版本,而 Q2 或 Q3 對模型表現影響太大所以不推薦使用。
最後,既然知道該下載哪個了,我們就用最簡單的方法 curl 下來吧:
curl -LO https://huggingface.co/audreyt/Taiwan-LLaMa-v1.0-GGML/resolve/main/Taiwan-LLaMa-13b-1.0.ggmlv3.q5_K_M.bin
雖然目前有個大略的方向,但實際上要用哪一種量化模型還是取決於任務的需求。
我們已經學會 GGML 各個檔案代表的意思,以後就可以自己挑選囉!
好啦,今天就這樣,明天見~

